O Brasil está entrando em uma nova fase em sua infraestrutura fiscal e de registro empresarial. A Receita Federal do Brasil anunciou formalmente uma mudança estrutural no CNPJ (Cadastro Nacional da Pessoa Jurídica)—o identificador nacional utilizado em todas as operações corporativas, fiscais e financeiras.
A partir de julho de 2026, os novos CNPJs deixarão o formato tradicional de 14 dígitos numéricos e passarão a adotar um formato alfanumérico de 14 caracteres. Isso significa que, pela primeira vez, os identificadores de empresas no Brasil passarão a incluir letras e números, mantendo o mesmo tamanho e lógica estrutural.
Essa não é uma mudança superficial. Trata-se de uma resposta direta a uma limitação estrutural: o esgotamento das combinações numéricas disponíveis no modelo atual. Com o crescimento acelerado na abertura de empresas—impulsionado pela digitalização, fintechs e formalização regulatória—o espaço numérico existente está se aproximando do limite.
O novo formato preserva a estrutura conceitual do CNPJ:
- Um identificador raiz da entidade jurídica
- Um segmento de filial/ordem
- Dois dígitos verificadores para validação
No entanto, ao introduzir caracteres alfanuméricos, a capacidade de combinações cresce exponencialmente—garantindo escalabilidade para as próximas décadas.
É importante destacar que essa mudança se aplica apenas a novos registros. Empresas já existentes manterão seus CNPJs numéricos atuais, evitando uma migração em massa na base cadastral. Porém, essa coexistência de formatos cria uma nova camada de complexidade para sistemas corporativos, que precisarão suportar identificadores numéricos e alfanuméricos simultaneamente.
Para empresas reguladas que operam no Brasil—especialmente nos setores de bancos, seguros, saúde e manufatura—essa mudança marca o início de um prazo de adequação obrigatório. Embora julho de 2026 possa parecer distante, as mudanças necessárias nos sistemas são tudo menos simples.
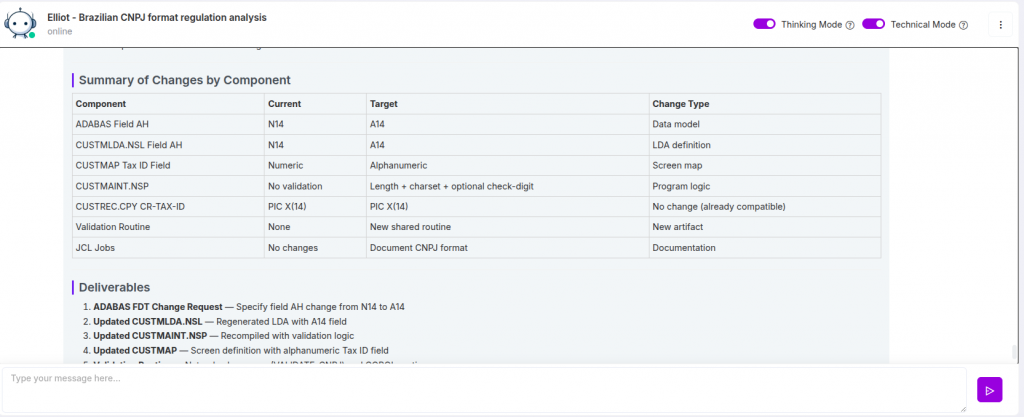
O que parece ser apenas uma alteração de formato é, na prática, uma mudança fundamental no modelo de dados—com impactos em todos os sistemas, integrações e processos que utilizam o CNPJ.
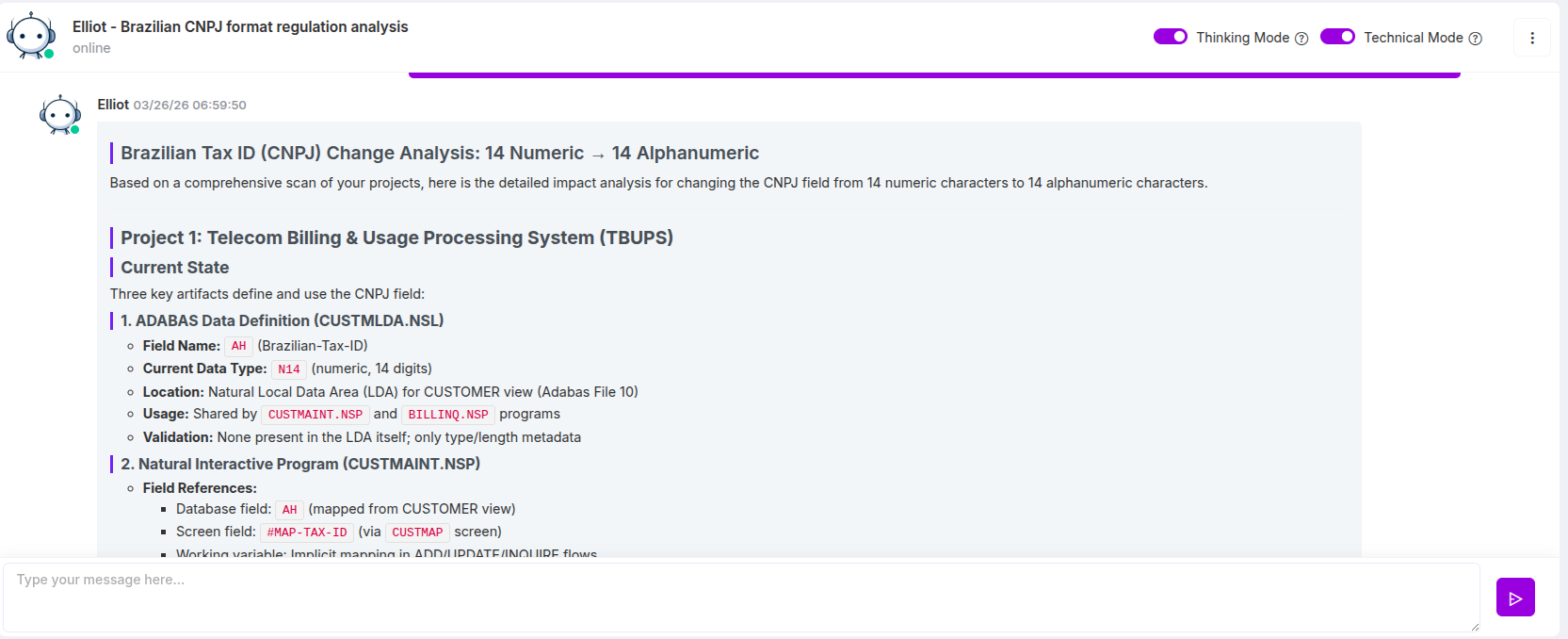

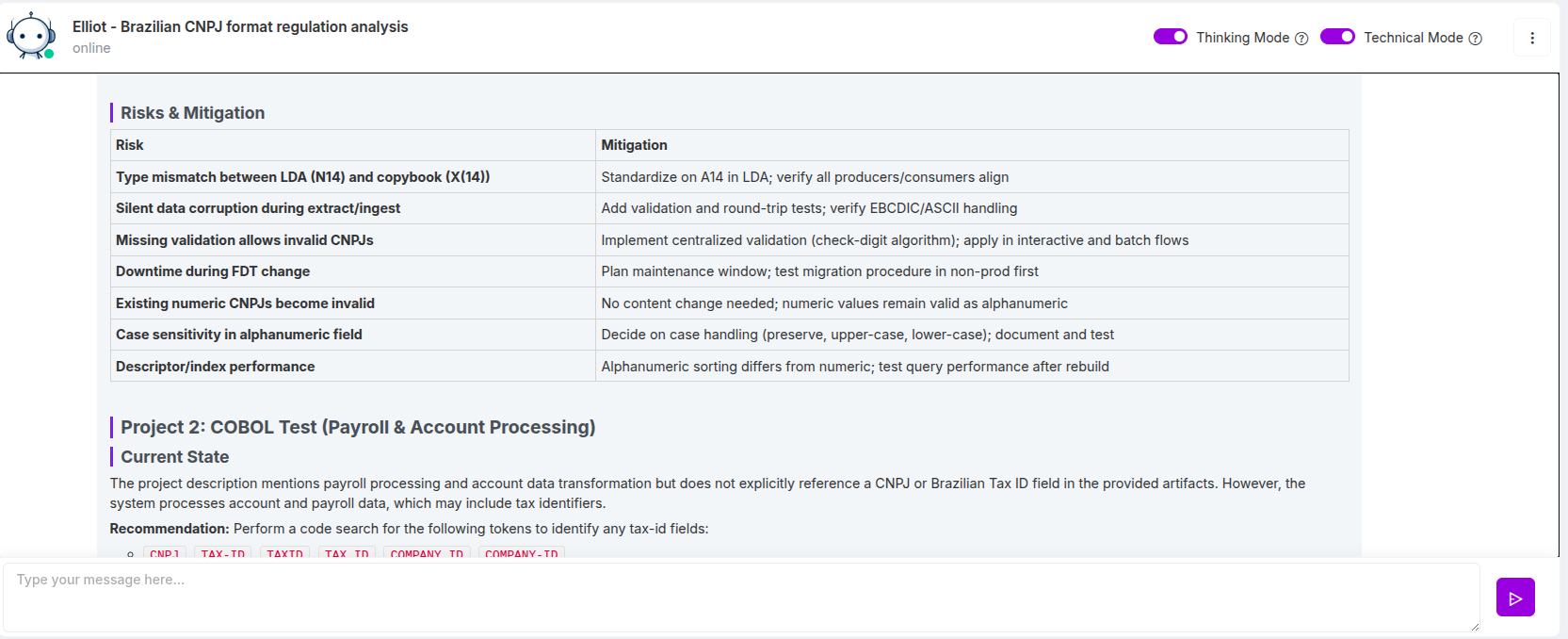
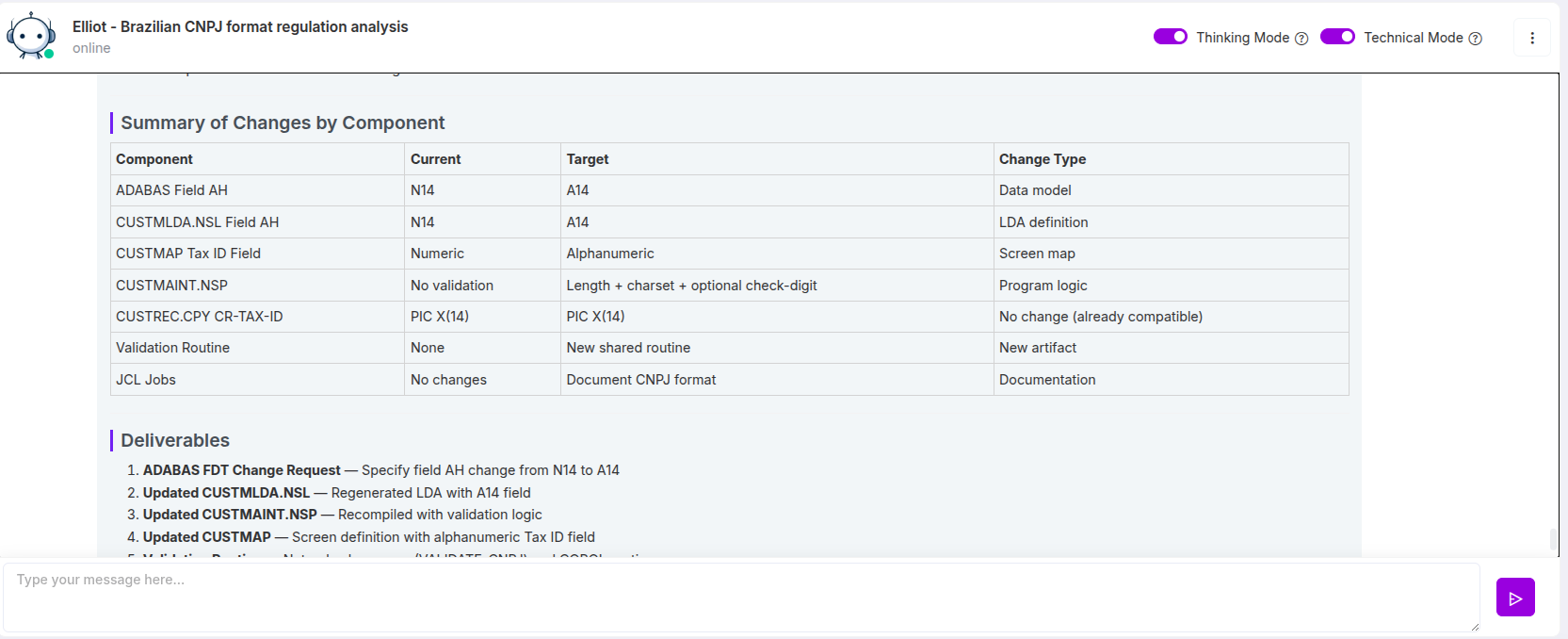
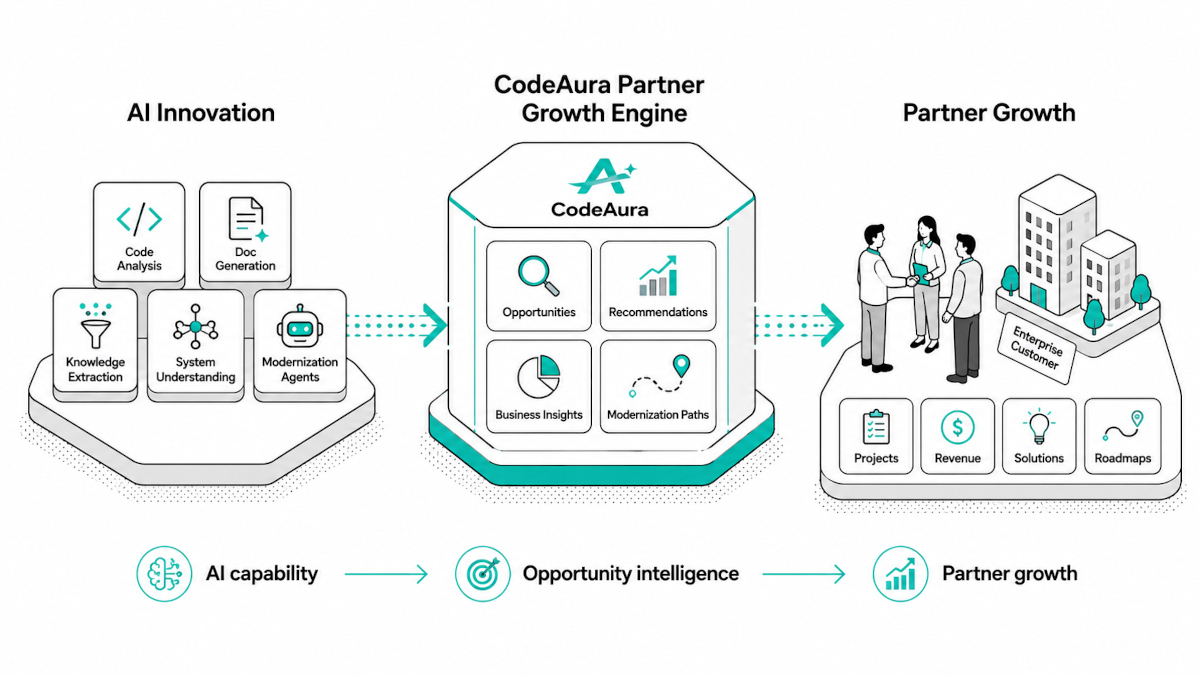
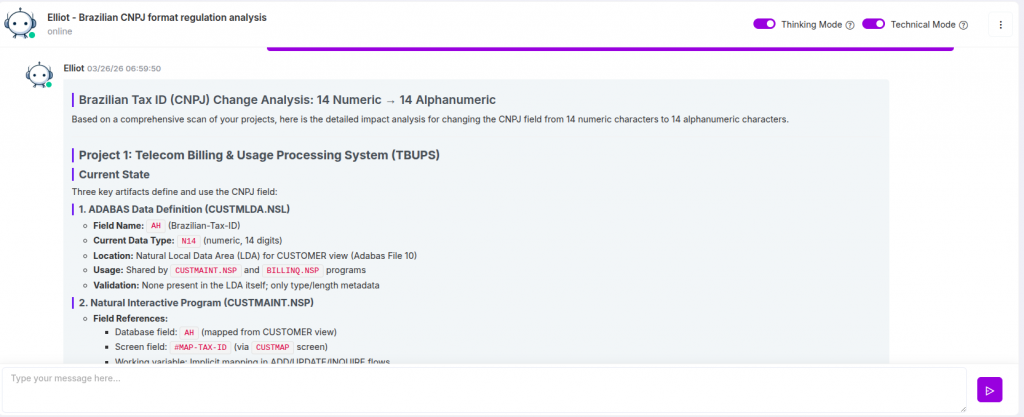
Como o CodeAura Identifica e Mapeia Dependências de CNPJ
Neste ponto, o desafio deixa de ser teórico. A pergunta passa a ser:
Como obter visibilidade completa—de forma rápida e confiável—em sistemas complexos e distribuídos?
É aqui que ferramentas tradicionais falham, e onde plataformas baseadas em IA como o CodeAura mudam completamente o cenário.
O CodeAura aborda o problema não como uma simples busca por palavras-chave, mas como uma análise contextual do sistema.
Em vez de apenas procurar “CNPJ” como texto, a plataforma entende:
- Onde o CNPJ é definido
- Como ele é validado
- Como ele flui entre sistemas
- Como é transformado, armazenado e consumido
Isso permite que as organizações saiam de uma descoberta fragmentada para um mapeamento completo de dependências.
Da Busca para o Entendimento
Os agentes de IA do CodeAura analisam bases de código em múltiplas linguagens—COBOL, Java, SQL, APIs—e identificam automaticamente:
- Todas as ocorrências de uso do CNPJ (inclusive indiretas)
- Lógicas de validação (regras numéricas, regex, dígitos verificadores)
- Definições de tipo de dado (numérico vs string)
- Transformações ao longo de serviços e pipelines
E o mais importante: isso é feito sem depender de nomes consistentes ou documentação.
Isso elimina um dos maiores riscos em ambientes legados:
dependências ocultas que abordagens manuais não conseguem detectar.
Análise de Impacto e Modernização Segura em Escala
Uma vez identificadas as dependências, o desafio deixa de ser descoberta e passa a ser execução.
E é nesse ponto que muitos esforços de modernização falham—não por falta de conhecimento sobre o que mudar, mas pela incapacidade de prever o impacto dessas mudanças.
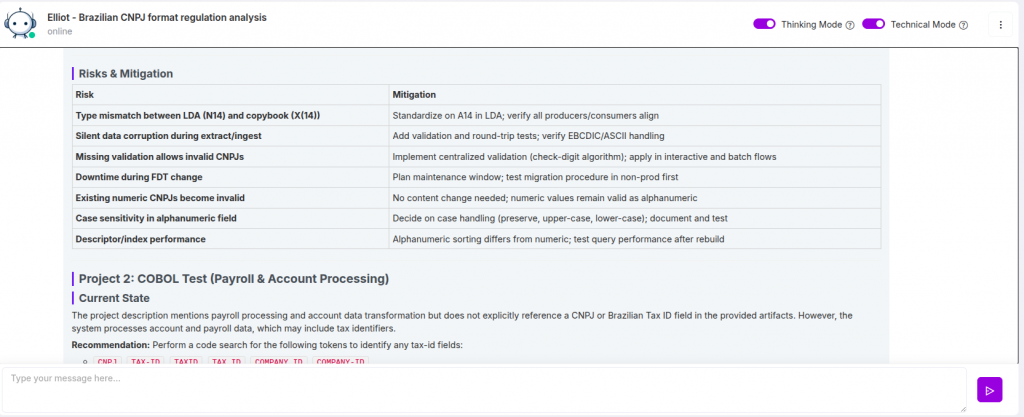
No contexto da transição do CNPJ, cada alteração traz riscos:
- Alterar um tipo de dado pode afetar sistemas downstream
- Atualizar validações pode invalidar processos existentes
- Ajustar transformações pode quebrar integrações e relatórios
Sem visibilidade de impacto, as organizações acabam adotando uma abordagem defensiva:
- Testando tudo excessivamente
- Atrasando entregas
- Aceitando riscos em produção
Esse modelo não é eficiente nem sustentável—especialmente com um prazo regulatório definido.
Da Mudança para a Consequência
O CodeAura resolve esse problema ao permitir análise de impacto antes da mudança.
Antes de qualquer modificação, a plataforma:
- Simula a propagação das mudanças entre sistemas
- Identifica todos os componentes afetados
- Destaca áreas críticas (faturamento, compliance)
- Revela dependências ocultas
Isso transforma a gestão de mudanças de reativa para preditiva e controlada.
Descubra como seus sistemas vão lidar com o CNPJ alfanumérico antes de 2026 com o CodeAura.

Prazos, Escopo e o Que Realmente Muda
Em qualquer mudança regulatória, a má interpretação do escopo e dos prazos é uma das principais fontes de risco para as empresas. A reforma do CNPJ não é diferente.
De acordo com a Receita Federal do Brasil, a transição para o formato alfanumérico terá início em julho de 2026, e sua aplicação foi cuidadosamente delimitada para evitar impactos imediatos na base cadastral.
Primeiro, é fundamental entender o que não muda. Empresas já existentes não terão seus CNPJs alterados ou reemitidos. Não haverá migração em massa, nem conversão retroativa dos registros atuais. Essa decisão reduz o impacto operacional imediato, mas cria uma nova realidade técnica: a coexistência de dois formatos.
Segundo, o novo formato se aplica exclusivamente a novas pessoas jurídicas. A partir da data de vigência, toda nova empresa registrada no Brasil receberá um CNPJ alfanumérico de 14 caracteres, enquanto empresas antigas continuarão utilizando seus identificadores numéricos.
Terceiro, embora o tamanho e a estrutura permaneçam os mesmos, a lógica de validação muda de forma significativa:
- Sistemas precisarão aceitar caracteres alfabéticos (A–Z)
- Questões como sensibilidade a maiúsculas/minúsculas e codificação passam a ser relevantes
- O cálculo dos dígitos verificadores deverá considerar entradas alfanuméricas
É nesse ponto que muitas organizações subestimam o impacto. A suposição de que “14 caracteres continuam sendo 14 caracteres” leva à negligência de dependências críticas em:
- Camadas de validação de entrada
- Estruturas de banco de dados
- Contratos de API
- Formatos de troca de dados (XML, JSON para NF-e e obrigações fiscais)
Outro equívoco comum é confundir formatação (pontos, barras, hífens) com o identificador em si. Esses elementos são apenas de apresentação, enquanto os sistemas internos frequentemente assumem um formato estritamente numérico—algo que deixará de ser válido.
Do ponto de vista de compliance, julho de 2026 não é apenas uma atualização técnica—é um marco obrigatório. Sistemas que não estiverem preparados para processar CNPJs alfanuméricos correm o risco de:
- Rejeitar parceiros comerciais válidos
- Falhar na validação de documentos fiscais
- Quebrar integrações críticas
Em resumo, o escopo regulatório pode parecer limitado no papel, mas, na prática, ele cria uma bifurcação permanente nos padrões de identificação, que todos os sistemas corporativos precisarão suportar.
Por Que Essa Mudança É Maior do Que Parece
À primeira vista, a transição para um CNPJ alfanumérico pode parecer uma mudança incremental—apenas uma ampliação dos caracteres permitidos em um identificador já existente. No entanto, dentro de ambientes corporativos, esse tipo de alteração raramente permanece isolado. Ela se propaga.
O CNPJ não é apenas um campo em um banco de dados. Ele é um identificador fundamental, presente em toda a arquitetura tecnológica da empresa. Desde sistemas bancários centrais até motores de faturamento, de plataformas de compras a pipelines de reporte regulatório, o CNPJ funciona como uma chave primária de identidade empresarial.
Isso significa que a mudança não afeta apenas uma aplicação ou módulo específico. Ela impacta uma rede de sistemas interdependentes, muitos dos quais foram construídos com a premissa de que o CNPJ é exclusivamente numérico.
Na prática, o CNPJ está profundamente enraizado em:
- Sistemas de dados mestres (clientes, fornecedores, parceiros)
- Plataformas ERP e razão financeira
- Sistemas de faturamento eletrônico (NF-e, CT-e, SPED)
- Modelos de crédito e risco
- Data warehouses e pipelines analíticos
- Integrações via API com terceiros e órgãos governamentais
O desafio não está apenas em onde o CNPJ é armazenado, mas em como ele é utilizado.
Em muitos sistemas, o CNPJ é:
- Utilizado em lógica de ordenação e indexação
- Parte de chaves compostas
- Processado e transformado entre serviços
- Validado por regras numéricas fixas
- Assumido como compatível com tipos de dados numéricos
Essas premissas frequentemente não estão documentadas e foram distribuídas ao longo de anos—ou até décadas—de evolução dos sistemas.
Como resultado, o que parece ser uma simples “mudança de formato” rapidamente se transforma em um problema sistêmico de dependências. Uma única falha no tratamento de valores alfanuméricos pode gerar efeitos em cadeia, como:
- Inconsistências de dados entre sistemas
- Falhas em integrações com autoridades fiscais
- Relatórios incorretos
- Erros em processos downstream
Mais crítico ainda: esses problemas nem sempre aparecem de forma imediata. Muitas vezes surgem como inconsistências silenciosas, tornando sua detecção e correção muito mais complexas.
Por isso, a mudança do CNPJ deve ser entendida não como uma simples atualização de formato, mas como um evento de transformação de identidade em toda a organização.
O Desafio dos Sistemas Legados: Onde Tudo Quebra
Se sistemas modernos já enfrentam desafios relevantes com essa mudança, é nos ambientes legados que o impacto do novo CNPJ se torna realmente complexo—e arriscado.
Em diversos setores regulados no Brasil, muitos sistemas centrais ainda operam sobre arquiteturas antigas, frequentemente baseadas em COBOL, mainframes e monólitos altamente acoplados. Esses sistemas foram projetados com premissas rígidas sobre formatos de dados—premissas que agora deixam de ser válidas.
O problema central não é apenas a idade dos sistemas, mas sim a rigidez estrutural combinada com baixa visibilidade.
Nos sistemas legados, o CNPJ frequentemente é:
- Armazenado como tipo numérico (ex:
PIC 9em COBOL, INTEGER em bancos de dados) - Definido em campos de tamanho fixo, com lógica posicional rígida
- Validado por rotinas hardcoded que rejeitam qualquer caractere não numérico
- Processado em rotinas batch, onde desvios de formato podem interromper execuções
- Replicado em múltiplos sistemas sem uma fonte única de verdade
A simples introdução de caracteres alfanuméricos quebra imediatamente essas premissas.
Por exemplo:
- Um programa COBOL que espera apenas dígitos irá falhar nas validações
- Uma coluna de banco definida como INTEGER irá rejeitar valores alfanuméricos
- Um job batch baseado em posições fixas pode interpretar dados incorretamente, causando corrupção
- Sistemas downstream podem falhar ou descartar registros silenciosamente
O que torna esse cenário ainda mais desafiador é que essas dependências raramente estão centralizadas ou documentadas. Elas estão distribuídas em:
- Milhares de programas e scripts
- Pipelines de ETL legados
- Procedures e triggers em banco de dados
- Camadas de integração construídas ao longo de anos
Em muitos casos, as organizações já não possuem os desenvolvedores originais ou a documentação necessária para compreender completamente esses sistemas. Isso faz com que até mesmo identificar onde o CNPJ é utilizado seja uma tarefa complexa.
Como consequência, a adequação não é apenas uma atualização técnica—ela se torna um problema de descoberta em escala corporativa.
Além disso, existe o risco de efeitos colaterais não previstos. Alterar um tipo de dado ou regra de validação em um sistema pode impactar dezenas de processos dependentes. Sem visibilidade completa, as equipes acabam recorrendo a:
- Revisões manuais extensas de código
- Ciclos de teste baseados em tentativa e erro
- Alto custo de regressão
- Riscos em produção devido à cobertura incompleta
É por isso que ambientes legados estão mais expostos. A mudança do CNPJ não cria nova complexidade—ela expõe a complexidade que já existia.
O Risco Oculto: Compliance, Receita e Interrupções Operacionais
Até aqui, o desafio técnico já está claro. Mas, para líderes empresariais, a pergunta principal não é o quão complexa é a mudança—e sim: o que acontece se errarmos?
O CNPJ está no centro do ecossistema fiscal e comercial brasileiro. Quando sua integridade é comprometida, o impacto não se limita aos sistemas de TI—ele afeta diretamente o fluxo de receita, a conformidade regulatória e as operações do dia a dia.
Uma das áreas de risco mais imediatas é o faturamento eletrônico, especialmente no contexto da NF-e. Se um sistema não conseguir processar corretamente um CNPJ alfanumérico:
- Notas fiscais podem ser rejeitadas pelas autoridades fiscais
- Transações podem ser bloqueadas antes de sua conclusão
- O reconhecimento de receita pode ser atrasado ou invalidado
Em setores de alto volume, como bancos, seguros e manufatura, mesmo uma pequena taxa de falha pode gerar impactos financeiros significativos em poucos dias.
Além do faturamento, a gestão de parceiros e fornecedores se torna outro ponto crítico. Sistemas que não aceitam ou validam o novo formato podem:
- Rejeitar clientes ou fornecedores legítimos
- Falhar em processos de onboarding
- Gerar inconsistências nos dados mestres
Isso cria atritos não apenas internamente, mas em todo o ecossistema de negócios—afetando relações comerciais, contratos e entrega de serviços.
Do ponto de vista de compliance, os riscos são ainda mais graves. Empresas reguladas precisam garantir que todos os dados reportados estejam alinhados com os padrões governamentais. Falhas no tratamento do novo formato de CNPJ podem resultar em:
- Erros em reportes regulatórios
- Apontamentos em auditorias e penalidades
- Maior nível de fiscalização por órgãos reguladores
Para Chief Risk Officers (CROs), esse não é um cenário hipotético—é um gap de compliance previsível caso os sistemas não sejam atualizados a tempo.
Operacionalmente, as interrupções podem ser tanto visíveis quanto invisíveis. Alguns problemas serão imediatos—erros de sistema, transações rejeitadas, integrações quebradas. Outros serão silenciosos, como:
- Dados desalinhados entre sistemas
- Propagação incompleta de informações
- Relatórios e análises incorretos
Essas falhas silenciosas são particularmente perigosas, pois comprometem a confiança nos dados sem gerar alertas claros.
Para CFOs, o impacto é direto:
- Atraso na receita
- Aumento de custos operacionais
- Esforços emergenciais de correção
Para CIOs e CTOs, o desafio é sistêmico:
- Garantir a prontidão de ponta a ponta dos sistemas
- Evitar falhas em cascata nas integrações
- Gerenciar a mudança sem interromper operações
Nesse contexto, a reforma do CNPJ não é apenas uma atualização regulatória—é um evento de risco para a continuidade do negócio.
Organizações que tratarem essa mudança como algo menor provavelmente reagirão sob pressão. Já aquelas que adotarem uma abordagem proativa terão a oportunidade de reduzir riscos, modernizar seus sistemas e fortalecer sua conformidade simultaneamente.
Por Que Abordagens Tradicionais Não São Suficientes
Neste ponto, a maioria das organizações já reconhece a necessidade de agir. A resposta natural é mobilizar equipes internas, iniciar revisões de código e começar a atualizar regras de validação. No papel, isso parece razoável. Na prática, raramente escala.
O problema fundamental é que abordagens tradicionais dependem de descoberta manual em ambientes com baixa visibilidade.
Para se adaptar ao novo CNPJ alfanumérico, as equipes precisam responder a uma pergunta aparentemente simples:
Onde o CNPJ é utilizado em toda a organização?
Em sistemas modernos, isso pode ser rastreável. Em ambientes legados, não.
As referências ao CNPJ geralmente estão:
- Distribuídas em milhares de arquivos e programas
- Embutidas em nomes de variáveis inconsistentes ou abreviados
- Escondidas em rotinas de validação e manipulação de strings
- Referenciadas indiretamente por estruturas intermediárias
Isso transforma uma atualização pontual em um problema de busca em larga escala, sem limites claros.
Onde as Abordagens Tradicionais Falham
A maioria das empresas tenta uma combinação de:
- Busca por palavras-chave no código
- Revisões manuais
- Entrevistas com especialistas (SMEs)
- Ciclos incrementais de testes
Cada uma dessas abordagens apresenta limitações críticas:
- Buscas por palavra-chave perdem contexto
(ex: CNPJ armazenado com nomes diferentes) - Revisões manuais são lentas e sujeitas a erros
(especialmente em COBOL, SQL, Java e integrações) - Conhecimento dos especialistas é incompleto ou desatualizado
(muitos sistemas evoluíram além da documentação original) - Testes acontecem tarde demais
(problemas aparecem após mudanças já implementadas)
O resultado é um processo de adequação:
- Demorado
- Incompleto
- Arriscado
O Problema da Escala
Em grandes empresas, é comum encontrar:
- Mais de 10.000 referências ao CNPJ
- Dezenas de integrações
- Lógicas de validação duplicadas
Tentar mapear e corrigir isso manualmente resulta em:
- Dependências não identificadas
- Defeitos de regressão
- Atrasos no cronograma
Isso é especialmente crítico considerando o prazo regulatório fixo de julho de 2026.
Como o CodeAura Identifica e Mapeia Dependências de CNPJ
Neste ponto, o desafio deixa de ser teórico. A pergunta passa a ser:
Como obter visibilidade completa—de forma rápida e confiável—em sistemas complexos e distribuídos?
É aqui que ferramentas tradicionais falham, e onde plataformas baseadas em IA como o CodeAura mudam completamente o cenário.
O CodeAura aborda o problema não como uma simples busca por palavras-chave, mas como uma análise contextual do sistema.
Em vez de apenas procurar “CNPJ” como texto, a plataforma entende:
- Onde o CNPJ é definido
- Como ele é validado
- Como ele flui entre sistemas
- Como é transformado, armazenado e consumido
Isso permite que as organizações saiam de uma descoberta fragmentada para um mapeamento completo de dependências.
Da Busca para o Entendimento
Os agentes de IA do CodeAura analisam bases de código em múltiplas linguagens—COBOL, Java, SQL, APIs—e identificam automaticamente:
- Todas as ocorrências de uso do CNPJ (inclusive indiretas)
- Lógicas de validação (regras numéricas, regex, dígitos verificadores)
- Definições de tipo de dado (numérico vs string)
- Transformações ao longo de serviços e pipelines
E o mais importante: isso é feito sem depender de nomes consistentes ou documentação.
Isso elimina um dos maiores riscos em ambientes legados:
dependências ocultas que abordagens manuais não conseguem detectar.